
Senior Systems Engineering: Where Infrastructure Discipline Meets Modern Automation
Senior systems engineering is one of those disciplines that rarely gets attention when everything is working, but quickly becomes critical when something breaks.
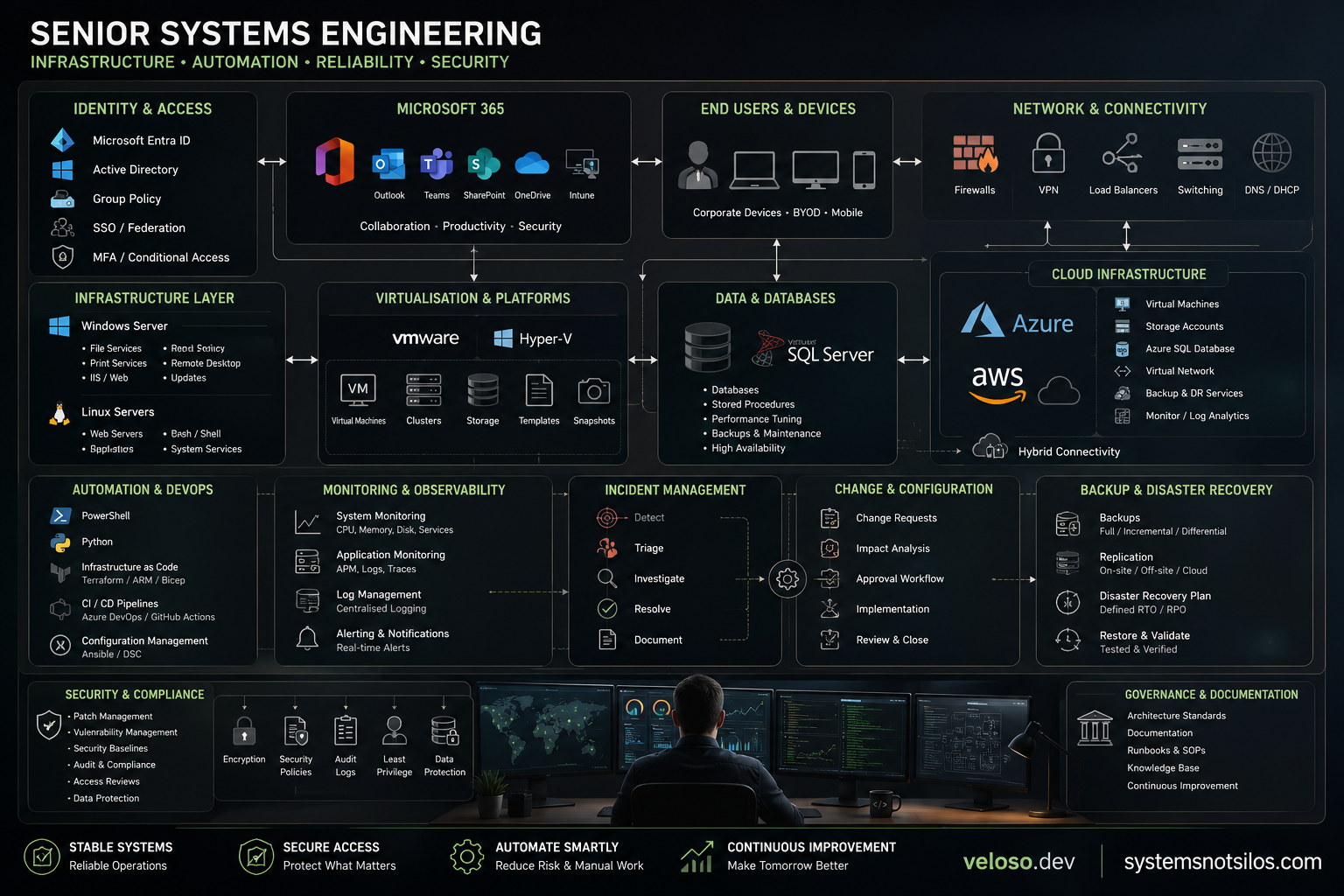
The role is not just about keeping servers online.
It is about understanding how an organisation really operates through its infrastructure, identity systems, databases, integrations, cloud services, monitoring, backups, support processes, security controls, and operational dependencies.
Modern infrastructure has changed a lot.
We now work with cloud infrastructure, Microsoft 365, Entra ID, SSO, DevOps practices, Infrastructure as Code, automation, virtualisation, CI/CD, observability, and hybrid environments.
But the old discipline still matters.
The best systems engineers I have worked with, or tried to model myself after, are not just tool operators. They are careful problem solvers.
They know how to troubleshoot under pressure.
They understand that a production issue may start as a user complaint. Still, the real cause may sit somewhere between Active Directory, Group Policy, SQL, Linux, Windows Server, a cloud service, an API, a scheduled job, a failed certificate, a vendor dependency, or a change that looked harmless at the time.
That is why structured thinking matters.
What changed?
What depends on what?
Which system is authoritative?
Where is the failure actually occurring?
Is this an identity issue, a capacity issue, a configuration issue, a data issue, a network issue, or an application issue?
Can we fix it safely?
Can we prevent it from happening again?
That mindset sits at the intersection of systems engineering, platform engineering, software engineering, and solution architecture.
Some of the most valuable engineering improvements are not always the most glamorous ones.
They are things like:
turning repeated manual support steps into scripts
improving documentation so the next person is not guessing
reducing data-processing work from days to hours
making environments easier to reproduce
making releases safer through better validation
improving monitoring so issues are found earlier
cleaning up fragile integrations before they become business risks
I have always respected engineering work that makes systems easier to support, recover, improve, and trust.
A reliable environment is not created by tools alone. It is created by disciplined people, effective change control, strong documentation, practical automation, careful root-cause analysis, and a culture that values continuous improvement.
For large-scale environments, especially those supporting public services, transport, safety, infrastructure, logistics, managed services, or critical business operations, the target should be simple:
stable systems
secure access
clear ownership
repeatable processes
fast but careful response
automation that reduces risk
documentation that helps the next engineer
continuous improvement that makes the environment stronger over time
Modernisation is important.
But modernisation without operational discipline only creates a newer kind of fragility.
The real value is in building and supporting systems that people can rely on when the pressure is on.
#SeniorSystemsEngineer #SystemsEngineering #Infrastructure #CloudInfrastructure #Microsoft365 #ActiveDirectory #WindowsServer #Linux #SQL #PowerShell #Automation #DevOps #InfrastructureAsCode #EntraID #SSO #IncidentManagement #RootCauseAnalysis #ChangeManagement #DisasterRecovery #CyberSecurity #PlatformEngineering #SoftwareArchitecture #SolutionsArchitecture #TechnologyStrategy #EngineeringLeadership #VelosoDev #SystemsNotSilos #GumtreeDev